All my recent Stable Diffusion XL experiments have been on my Windows PC instead of my M2 mac, because it has a faster Nvidia 2060 GPU with more memory. But today, I’m curious to see how much faster diffusion has gotten on a M-series mac (M2 specifically).
Some recent innovations have improved the performance of Stable Diffusion derived models on M-series (M1/M2/M3) macs:
- First, distillation has resulted in models like Segmind’s SSD-1B which is “50% smaller and 60% faster”.
- Second, rather than having to painfully convert models to Apple’s CoreML format, like I did back in December 2022, a community has started to share converted Core ML Models on Hugging Face
- Last but not least, someone has created Core ML Suite for ComfyUI, which contains nodes for using Core ML models in ComfyUI!
Let’s see if CoreML models are the fastest...
BTW, I know there are LCM LoRAs, but the inputs and the outputs are wildly different than with the original model. So, I can’t test them with the same number of steps or sampler-scheduler, so any comparison would not be meaningful.
Installing ComfyUI Core ML Suite
If you have been following my series, you already know how to install SDXL with ComfyUI.
If not, here is the script. I am using the version of Python that comes installed on macOS Sonoma 14.1.1, which is Python 3.9.6.
I also install cg-quicknodes, which is a simple widget that displays the startup time, the time spent on each node, and the total time of each run.
In a working folder, execute these commands (when using zsh delete the # comment lines, whereas bash will happily ignore them):
# get ComfyUI
git clone https://github.com/comfyanonymous/ComfyUI
cd ComfyUI
# create virtual environment and install required libraries
python3 -m venv v
source v/bin/activate
pip install -r requirements.txt
pip install torchvision
# get ComfyUI-CoreMLSuite and install required libraries
cd custom_nodes
git clone https://github.com/aszc-dev/ComfyUI-CoreMLSuite
cd ComfyUI-CoreMLSuite
pip install -r requirements.txt
cd ..
# get cg-quicknodes
git clone https://github.com/chrisgoringe/cg-quicknodes
cd ../..Download Models
I’ll be using coreml-SSD-1B_8bit which is only trained at one resolution, 768x768.
- Download the file SD-1B_original_8bit_768x768.zip and extract.
- Copy the folder
Unet.mlmodelcto ComfyUI’smodels/unetfolder. - I rename the folder to
ssd-1b.768x768.mlmodelcfor clarity, but this is optional.
Currently, ComfyUI-CoreMLSuite can only load the UNet model, but not the Text Encoder or VAE .mlmodelc files. Instead I use the original files from the original SSD-1B model - I’m downloading the half precision float16 (fp16) versions mainly to save disk space, but I think CoreML will convert to float32 (fp32) anyway, so perhaps you prefer to get that version. More on this later...
- Download the first text encoder text_encoder/model.fp16.safetensors...
- Save it to
models/clipand rename e.g. tossd1b-clip.fp16.safetensors. - Download the second text encoder text_encoder_2/model.ftp16.safetensors...
- Save it to
models/clipand rename e.g. tossd1b-clip2.fp16.safetensors. - Download the VAE vae/diffusion_pytorch_model.fp16.safetensors...
- Save it to
models/vaeand rename e.g. tossd1b-vae.fp16.safetensors.
Finally, start python main.py --force-fp16 or just python main.py for the fp16 and fp32 versions respectively. Then open your browser to http://127.0.0.1:8188.
Fixing an CoreMLSuite Error
I am using the version of Core ML Suite for ComfyUI with files last edited on 25 Nov 2023.
If you, like me, encounter this error, then I have the fix for you:
File "/ComfyUI/custom_nodes/ComfyUI-CoreMLSuite/coreml_suite/converter.py", line 318, in <module>
lora_weights: list[tuple[str | os.PathLike, float]] = None,
TypeError: unsupported operand type(s) for |: 'type' and 'ABCMeta'Edit the file custom_nodes/ComfyUI-CoreMLSuite/coreml_suite/converter.py. Search for this block and edit the code on line 318:
def convert(
ckpt_path: str,
model_version: ModelVersion,
unet_out_path: str,
batch_size: int = 1,
sample_size: tuple[int, int] = (64, 64),
controlnet_support: bool = False,
lora_weights: list[tuple[str | os.PathLike, float]] = None,
attn_impl: str = AttentionImplementations.SPLIT_EINSUM.name,
config_path: str = None,
):Remove the | os.PathLike bit, i.e. all you need is:
lora_weights: list[tuple[str, float]] = None,Save, then stop Control+C and re-start ComfyUI.
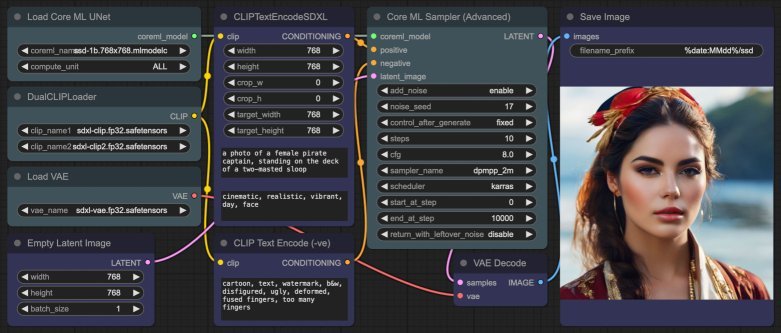
ComfyUI Workflow
Create the workflow below:
- Use the new CoreML node CoreMLUNetLoader to load the CoreML model - in terms of the
compute_unitsetting, from fastest to slowest isALL,CPU_AND_GPU,CPU_AND_NEand finallyCPU_ONLY(the last two are ~7-8x slower). - Since the UNet does not include the text encoders or VAE, use the DualCLIPLoader and VAELoader respectively - from my testing, getting the clip swapped makes no difference.
- And finally, do not use the standard KSamplerAdvanced node - instead, use the new CoreMLSamplerAdvanced node in its place.
Wire up and configure the rest similar to a standard ComfyUI workflow for SDXL.
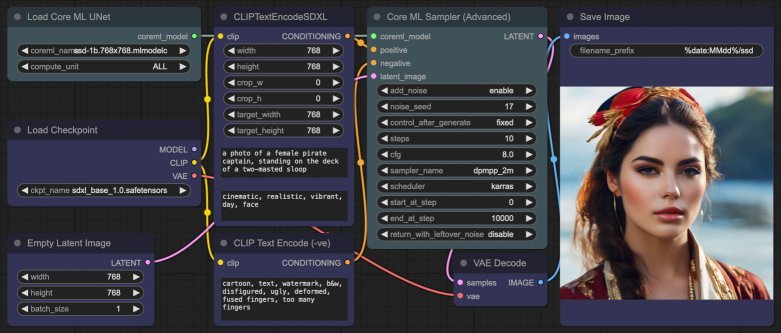
Using SDXL Base Baked-In Text Encoders and VAE
Having to download separate Text Encoder and VAE files and selecting the correct ones will be a pain...
But from what I can tell, falling back to either the original Stable Diffusion XL Base 1.0 sd_xl_base_1.0_0.9vae.safetensors or SSD-1B SSD-1B.safetensors, both work just as well. There is a slight performance penalty with this method compared to the previous, but at least I conserve disk space, since I already have the standard SDXL and SSD-1B model .safetensors files.
If you prefer this, then use the standard CheckpointLoaderSimple clip and vae outputs, and just ignore model.
Quick and Dirty Performance Comparison
I am too lazy to do an in-depth test, but here is what I did. All tests use the configuration with the same starting seed and batch size of 2 for three runs with 10 steps, dpmpp_2m karras and CFG 8.0. After each set, I re-start ComfyUI. This way, the first run is always the longest since it involves loading the model, and the next 2 runs use cached data, with only the seed incremented.
The relative speed is the percentage of time taken based on the total output from cg-quicknodes, relative to the original SDXL Base fp32 test.
| Model | Relative Speed | Comments |
|---|---|---|
| SDXL Base fp32 | 100% | SDXL produces the best and more varied images... |
| SDXL Base fp16 | 14.62% | ... but fp16 produces images with no noticable differences |
| CoreML SSD-1B + Model SSD-1B fp32 | 11.61% | Loading both CoreML and standard SSD-1B model is slower... |
| CoreML SSD-1B + Model SSD-1B fp16 | 11.54% | ... (with no significant difference between the fp16 and fp32 versions)... |
| CoreML SSD-1B fp32 | 10.27% | ... than loading separate Text Encoders and VAE |
| CoreML SSD-1B fp16 | 10.32% | CoreML is about the same comparing fp16 and fp32 |
| SSD-1B fp32 | 10.33% | This seems close the speed using either CoreML SSD-1B fp16 or fp32... |
| SSD-1B fp16 | 8.29% | ... but standard SSD-1B at half-precision is the fastest by a noticable margin! |
Alas, the CoreML version is not faster than the default for this specific SSD-1B model. But at least, SSD-1B is ~60% faster than SDXL.
So, my 2 cents... though mine is too small a sample set to make any definitive conclusions!
- SSD-1B at fp16 precision is the fastest model, cutting the time taken by a factor of 10 compared to SDXL fp32!
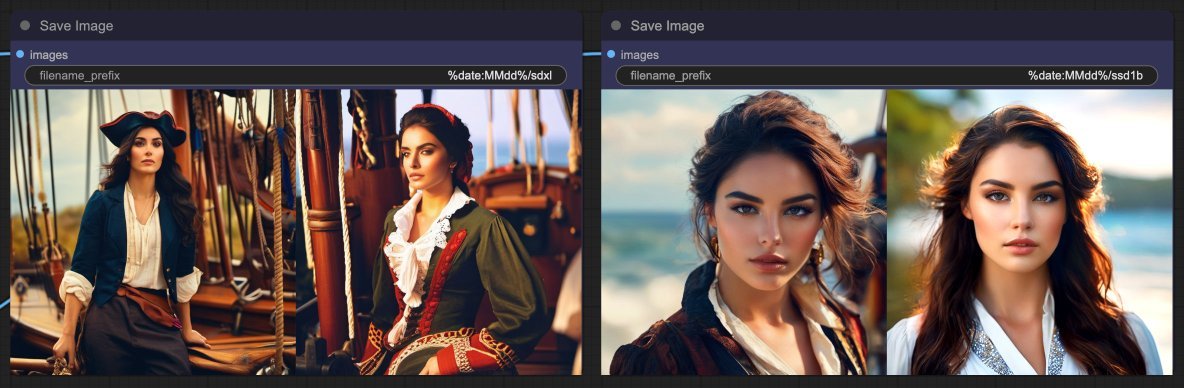
- Compared to SDXL fp16 though, SSD-1B fp16 takes only about 57% the time, but SDXL Base produces significantly better and more varied images for me - SSD-1B is biased towards rather boring forward facing portrait close ups as in the example below.
- CoreML SSD-1B is probably padding to fp32 and is about as fast as SSD-1B fp32... you can test if CoreML is faster for you, but it seems insignificant.
- Leveraging the CoreML model with the SSD-1B model’s baked in Text Encoders and VAE is slightly slower than loading the Text Encoders and VAE individually.
The set on the left is from SDXL Base 1.0, the one on the right is from SSD-1B, all being equal. Which would you rather?